Introducing clice —
My recent quest has been two-fold. To better understand software development processes within a GNU/Linux environment and to improve my working knowledge of SQL.
Although familiar with coding on Linux I’m unfamiliar with code analysis tools, only recently started using Git and GNU Make and have yet to venture into using GNU Configure. I need to master these tools to make my own projects more shareable and to improve my chances of contributing to other projects.
SQL, on the other hand, is an area of technology that I’ve never found very interesting. SQL queries appear pretty basic in comparison to the low-level coding that I usually prefer. Yet whilst I’ve ignored SQL it has become ubiquitous and I now feel I need to catch-up.
Introducing clice:
clice is roughly an acronym for ‘command line coding ecosystem’, a project to provide tools that make coding from a basic Linux command line more productive. Such as:
1. Tools to manage source files and keep the coding environment tidy.
2. Tools to scan source and object code and maintain a documentation database.
3. Tools to navigate complex projects and their dependencies.
4. Tools to support the use of GNU Make, GNU Configure and Git.
I feel I should point out that I’m not opposed to a GUI environment and that I often use IDE’s (Integrated Development Environments) but creating your own tools is a great way to really learn about the underlying processes and, if you spend a lot of time coding, who wouldn’t want their own bespoke ecosystem.
All the code for clice is available under a GPLv3 licence from my GitHub account: https://github.com/agben/clice
I wouldn’t wish to impose my preferences on others though so feel free to use as much or as little as you need and to improve it to suit your own needs.
1. The coding environment:
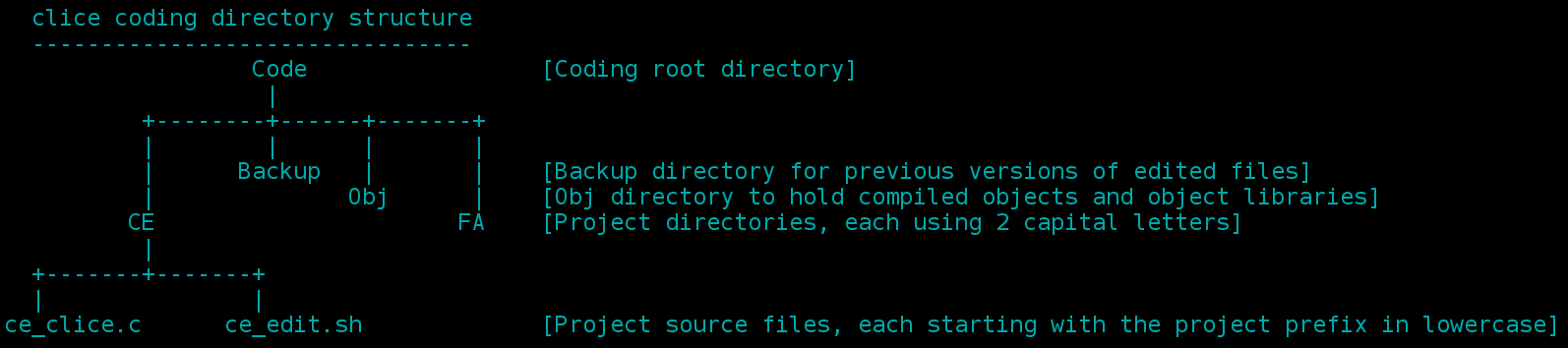
clice works within a set structure of directories and file naming conventions.
Individual projects sit below a master source code directory and each project directory name consists simply of two capital letters. e.g my clice project is coded as CE and sits in ~/Code/CE/
Each source code file within a project then uses the project code as a prefix, but in lowercase. e.g. some of the clice source files are ce_clice.c, ce_edit.sh, cef_main.c and ce_main_def.h
Also beneath the master coding directory there is ~/Code/Obj/ to hold object files and libraries and ~/Code/Backup/ to hold previous versions of edited files.
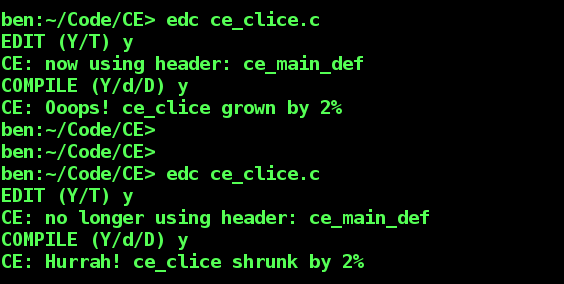
$ edc # move to the master coding directory ~/Code/ $ edc ce # move to the ce project directory ~/Code/CE/ $ edc cef_main.c # move to the ce project directory and present the following options EDIT (Y/T) # Y (or y) to edit the source file or T (or t) to touch it (mark as modified so tools like GNU Make will pick it up) COMPILE (Y/d/D) # compile normally (Y or y) or with debugging enabled (d for debug and D for debug with a pause after each diagnostic message)
Here edc can be used to navigate project folders and with bash auto-completion it can help you to find the right source file.
Furthermore edc checks if you’ve altered the source file or successfully compiled an object file and can initiate scans of each to identify changes.
2. Maintaining the clice database:
The clice database tracks useful metadata about your source programs, including their descriptions, function prototypes, sizes and details of any other functions or header files that they use. Key to the usefulness of clice is identification of the relational links between these modules. Between the functions and headers that you have created and those that have been included from other libraries.
When using edc to edit a source file, a scan of that file is made to identify any changes to the clice metadata. The type of scan used is dependent on the programming language of the source file with ce_scan_bash used for shell scripts and ce_scan_c used for C programs or headers. I’ll add other language parsers in due course.
As well as scanning the source file I also use ctags to identify useful metadata from C programs.
When using edc to compile a program, a scan of the resulting object file is used to identify any changes to the clice metadata. This ce_scan_obj process doesn’t parse the raw object file but the results of an objdump analysis of it. Initially I used the GNU nm tool to identify symbols referenced by an object file but later found that GNU objdump (which is usually used as a disassembler) provided more useful output, especially if the source file contained multiple functions.
Each of these scans for clice metadata is automated by the edc process. Unlike some code management tools I want clice to be as simple as possible to use, with minimal configuration and no constraints or code formatting imposed.
If source code is good enough for the compiler then clice should cope with extracting metadata from it.
For my interest these scans of source and object files provide notification of any new relational links established or removed between clice modules (functions or headers). They also identify any percentage change in the size of compiled programs.
The size of a compiled program is no reflection of its runtime memory requirements or operational performance but, after making some code tweaks, I like to see what difference I’ve made to this first of many measures.
3. Navigating clice:
Having established the clice database and the tools to keep it up to date, without additional effort beyond my using edc for my editing and compiling, I next needed a means to explore its contents.
My answer was a tool called clice (naturally). A simple ncurses based set of menus that allowed me to search for programs or header files and display their metadata.
It’s at this point that I realised I’d created a very poor version of Cscope. Although I was always certain that something like clice must already exist but that wasn’t going to disuade me from developing my own tools. A project from which I could learn, whilst creating something tailored to my needs.
And indeed I find clice suits my needs for navigating projects. Where Cscope allows you to search programs, clice allows you to follow the links between modules e.g. which programs #include one of my header files?, pick one and see what functions it calls?, pick one and see what system functions it calls?, pick one and see if I have any other programs that use that system function?, and so forth. All simply by making selections from a list of what each clice module links to.

I also appreciate the feedback that edc provides after each edit and compilation and I’m sure I’ll find further uses for the clice database.
4. Software project management using clice:
This is still work in progress but at the very least I hope to use the clice database to generate GNU makefiles for each of my projects. I’ve been learning to use GNU make during the development of clice and my handcrafted makefiles can currently be found on my GitHub account. If you find they’ve been replaced by versions that say they were auto-generated by clice then you’ll know I’ve succeeded!
Alongside edc for editing code I’ve also added edm to edit makefiles using the script ce_edit_make.sh. So a simple edm ce will take you to the clice project directory (~/Code/CE/) and give you options to edit or run that project’s makefile.
Makefiles can be generated by CMake but for my needs I’m aiming for something simpler and with minimal configuration requirements. So far, despite directory and file naming formats and a requirement to use edc for code editing, clice hasn’t imposed any coding styles or required any form of configuration data to define each project. Although unfortunately the latter is now going to be a necessity but I intend to keep any config files as simple as possible.
As a starter I’ve created a .ce.clice config file and each of my project directories will have their own version. These files contain a project description which is displayed by clice when a list of projects is requested.
A project description is a poor excuse to impose project config files but I foresee the main need for these files will be the management of object libraries. i.e. a project may contain many functions but only those listed in the config file will end up in the project’s object library for linking with other projects.
And to maintain consistency these .[project].clice config files can be easily edited by using edp which runs the script ce_edit_project.sh i.e. edp ce to edit the clice project’s config file.
The code:
clice is written in C with dependencies on three object libraries that are also available from my GitHub account.
libgxtfa – provides ‘file access’ functions that will enable clice to utilise a variety of database engines. Currently requests from the clice filehandler cef_main are used to generate SQL for SQLite.
libgxtnc – provides a wrapper for ncurses functions with a view to making clice more easily portable to other command line (or even GUI) display frameworks.
libgxtut – provides wrappers for other utility functions that may be bespoke to a particular operating system.
The purpose of these libraries is to separate any services that could be considered unique to a particular architecture from the clice application. Thus making it easier to compile clice for a different operating system, database management system or user interface framework. Although admittedly those choices are currently limited to Linux, Sqlite and ncurses but at least adding more options is now a matter of updating these libraries and doesn’t require a rewrite of clice.
The code for this clice project is littered with #TODO notes with ideas for additional features or to flag code that I’m not happy with (working code doesn’t mean finished code). So improvements will follow but I’m providing this write-up now because clice has reached a stage where I find it useful as a software development tool.
Version numbers at the time of writing are:
clice – – v0.1.11.1
libgxtfa – v0.1.1.3
libgxtnc – v0.1.0.2
libgxtut – v0.1.0.0
Categorised as: Computer Stuff
Comments are disabled on this post